🚀OpenAI ha appena lanciato il nuovo modello o1, progettato per portare le capacità di problem-solving dell’IA a un livello superiore.
🔍 𝐂𝐨𝐬𝐚 𝐫𝐞𝐧𝐝𝐞 𝐨𝟏 𝐝𝐢𝐯𝐞𝐫𝐬𝐨?
Il modello o1 utilizza un algoritmo di reinforcement learning avanzato, basato sul metodo 𝑪𝒉𝒂𝒊𝒏 𝒐𝒇 𝑻𝒉𝒐𝒖𝒈𝒉𝒕, che lo aiuta a ragionare in modo più profondo e strutturato. Dai test interni emerge che le sue prestazioni migliorano progressivamente con l’addestramento e con un tempo di calcolo più lungo nella fase di test. Tuttavia, la scalabilità di questo processo è ancora in fase di sviluppo.
💡 𝐏𝐫𝐞𝐬𝐭𝐚𝐳𝐢𝐨𝐧𝐢
o1 eccelle nella risoluzione di problemi complessi in ambito scientifico, matematico e informatico, superando i modelli precedenti in molte competizioni di ragionamento logico. Tuttavia, questo comporta tempi di risposta leggermente più lunghi. Per i compiti creativi, invece, le sue performance sono paragonabili agli altri modelli.
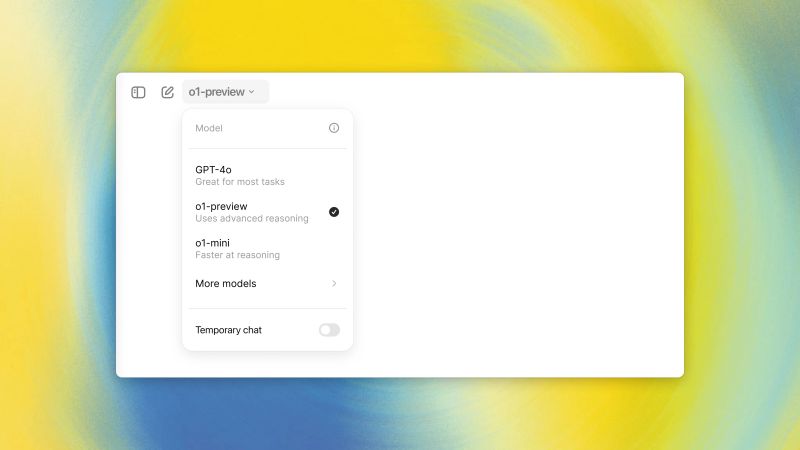
2️⃣ 𝐃𝐮𝐞 𝐯𝐞𝐫𝐬𝐢𝐨𝐧𝐢 𝐝𝐢𝐬𝐩𝐨𝐧𝐢𝐛𝐢𝐥𝐢
𝐨𝟏-𝐩𝐫𝐞𝐯𝐢𝐞𝐰: più performante, ideale per compiti complessi.
𝐨𝟏-𝐦𝐢𝐧𝐢: versione più veloce e accessibile, perfetta per task semplici.
Entrambi i modelli sono ancora in Beta, quindi potrebbero non coprire tutte le funzionalità dei predecessori.
🎯 𝐐𝐮𝐚𝐧𝐝𝐨 𝐮𝐬𝐚𝐫𝐥𝐨?
Se lavori su progetti strutturati e complessi come la programmazione avanzata o la ricerca scientifica, o1 potrebbe essere il partner ideale. Per task più semplici o creativi, i miglioramenti rispetto ai modelli esistenti potrebbero essere meno evidenti.
o1 non è un semplice passo avanti, ma un’evoluzione laterale: potenzia alcune capacità degli LLM, ma non rappresenta ancora una rivoluzione.
Fonte: https://lnkd.in/dqShy65C
Comments are closed